
 A LEVEL COMPUTING
A LEVEL COMPUTING Types of Language Theory
Types of Language Theory
4. Memory addressing
Low level languages have a number of ways to manipulate the content of main memory. These methods are called the 'memory modes'.
Each memory mode has its advantages and disadvantages and the programmer needs to understand which one should be used at any point within his code.
Immediate Addressing
This is the fastest method of addressing as it does not involve main memory at all. The data to be used is hard-coded into the instruction itself.
For example, you want to add 2 to to the content of the accumulator
The instruction is:
| ADC 2 |
Nothing has been fetched from memory, the instruction simply adds 2 to the accumulator immediately.
Immediate Addressing is very useful to carry out instructions involving constants (as opposed to variables). For example you might want to use 'PI' as a constant 3.14 within your code.
Direct (or Absolute) Addressing
This is a very simple way of addressing memory - the code refers directly to a location in memory
For example
| SUB (3001) |
In this instance the value held at the absolute location 3001 in RAM is subtracted from the accumulator.
The good thing about direct addressing is that it is fast (but not as fast as immediate addressing) the bad thing about direct addressing is that the code depends on the correct data always being present at same location. It is generally a good idea to avoid referring to absolute memory addresses in order to have 're-locatable code' i.e. code that does not depend on specific locations in memory.
You could use direct addressing on computers that are only running a single program. For example an engine management computer only ever runs the code the car engineers programmed into it, and so direct memory addressing is excellent for fast memory access.
Indirect Addressing
Many programs make use of software libraries that get loaded into memory at run time by the loader. The loader will most likely place the library in a different memory location each time.
So how does a programmer access the subroutines within the library if he does not know the starting address of each routine?
Answer: Indirect Addressing
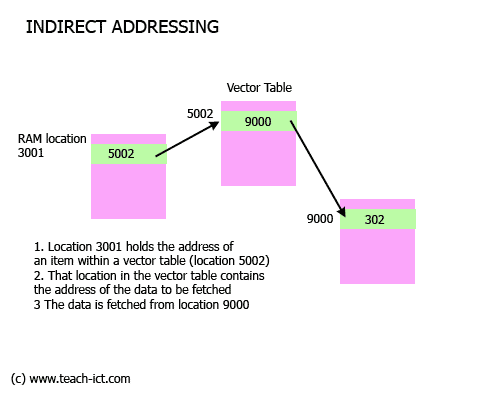
It works like this
1. A specific block of memory will be used by the loader to store the starting address of every subroutine within the library. This block of memory is called a 'vector table'. A vector table holds addresses rather than data. The application is informed by the loader of the location of the vector table itself.
2. In order for the CPU to get to the data, the code first of all fetches the content at RAM location 5002 which is part of the vector table.
3. The data it contains is then used as the address of the data to be fetched, in this case the data is at location 9000
A typical instruction would look like
| MOV A, @5002 |
This looks to location 5002 for an address. That address is then used to fetch data and load it into the accumulator. In this instance it is 302.
Indexed Addressing
Very often, a chunk of data is stored as a complete block in memory. For example, it makes sense to store arrays as contiguous blocks in memory. The array has a 'base address' which is the location of the first element, then an 'index' is used that adds an offset to the base address in order to fetch any other element within the array.

Index addressing is fast and is excellent for manipulating data structures such as arrays as all you need to do is set up a base address then use the index in your code to access individual elements.
Another advantage of indexed addressing is that if the array is re-located in memory at any point then only the base address needs to be changed. The code making use of the index can remain exactly the same.
Challenge see if you can find out one extra fact on this topic that we haven't already told you
Click on this link: Memory addressing methods
Copyright © www.teach-ict.com